MX4,MX6,MX9格式解读
我们先回顾量化的知识
(参考文献 With Shared Microexponents, A Little Shifting Goes a Long Way)
一、量化本质:从浮点到整数的数值映射
FP32 转 INT8 的核心是将 32 位浮点数映射到 8 位整数,过程如下:
值域压缩
FP32 的动态范围约为 ±10³⁸,精度由尾数(23 位)决定;INT8 范围为 - 128~127(有符号),需通过缩放因子(Scale) 将浮点值域压缩到整数范围。
例:若 FP32 数据分布在 [-10, 10],Scale = 10 / 127 ≈ 0.0787,INT8 数值x对应的浮点值为x * Scale。
映射公式
浮点值f → INT8 值q:q = clamp(round(f / Scale), -128, 127)
反向还原:f_recovered = q * Scale
二、硬件执行:INT8 运算单元为例
使用 INT8 专用运算单元:
硬件支持:现代 AI 芯片(如 GPU、TPU、NPU)通常集成 INT8 加速单元,直接处理整数矩阵乘法。
例:NVIDIA GPU 的 Tensor Core 支持 INT8 张量运算,通过INT8 GEMM(通用矩阵乘法)指令实现。
执行流程:
模型量化后,权重和激活值存储为 INT8 格式;
硬件读取 INT8 数据,通过整数乘法器(如 16×16 INT8 乘法)计算乘积;
累加结果后,通过 Scale 还原为浮点值(用于后续层输入或输出)。
三、总结
量化部署是算法与硬件深度结合的过程:通过数学映射将浮点数转换为整数,减少计算和存储开销,同时借助硬件指令集(如 SIMD,Tensor Core)和架构优化(如专用计算单元)提升执行效率。实际部署中需平衡精度、性能与硬件兼容性,通过工具链自动化和硬件定制化实现最优效果。
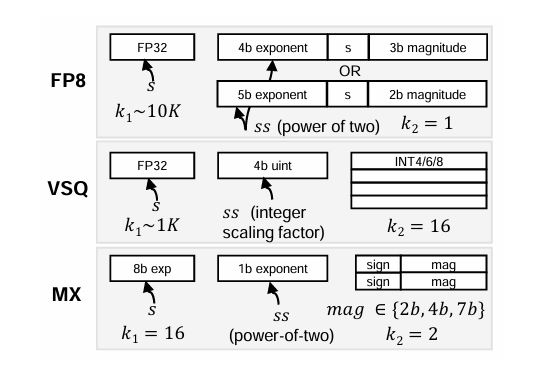
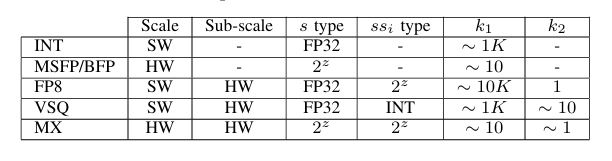
两级量化
概念
NV的VSQ技术首次引入了两级量化的概念,而普通的FP8量化可视为k2=1的特殊情况,MX4,6,9则是先将k1=16个元素的块进行缩放,然后将其分为8组,每组各有1位新的缩放因子,两种缩放因子构成两级缩放。
Comments